Part I: What is an information system?

Chapter 1: What Is an Information System?
Learning Objectives
Upon successful completion of this chapter, you will be able to:
- define what an information system is by identifying its major components;
- describe the basic history of information systems; and
- describe the basic argument behind the article “Does IT Matter?” by Nicholas Carr.
Introduction
Welcome to the world of information systems, a world that seems to change almost daily. Over the past few decades information systems have progressed to being virtually everywhere, even to the point where you may not realize its existence in many of your daily activities. Stop and consider how you interface with various components in information systems every day through different electronic devices. Smartphones, laptop, and personal computers connect us constantly to a variety of systems including messaging, banking, online retailing, and academic resources, just to name a few examples. Information systems are at the center of virtually every organization, providing users with almost unlimited resources.
Have you ever considered why businesses invest in technology? Some purchase computer hardware and software because everyone else has computers. Some even invest in the same hardware and software as their business friends even though different technology might be more appropriate for them. Finally, some businesses do sufficient research before deciding what best fits their needs. As you read through this book be sure to evaluate the contents of each chapter based on how you might someday apply what you have learned to strengthen the position of the business you work for, or maybe even your own business. Wise decisions can result in stability and growth for your future enterprise.
Information systems surround you almost every day. Wi-fi networks on your university campus, database search services in the learning resource center, and printers in computer labs are good examples. Every time you go shopping you are interacting with an information system that manages inventory and sales. Even driving to school or work results in an interaction with the transportation information system, impacting traffic lights, cameras, etc. Vending machines connect and communicate using the Internet of Things (IoT). Your car’s computer system does more than just control the engine – acceleration, shifting, and braking data is always recorded. And, of course, everyone’s smartphone is constantly connecting to available networks via Wi-fi, recording your location and other data.
Can you think of some words to describe an information system? Words such as “computers,” “networks,” or “databases” might pop into your mind. The study of information systems encompasses a broad array of devices, software, and data systems. Defining an information system provides you with a solid start to this course and the content you are about to encounter.
Defining Information Systems
Many programs in business require students to take a course in information systems . Various authors have attempted to define the term in different ways. Read the following definitions, then see if you can detect some variances.
- “An information system (IS) can be defined technically as a set of interrelated components that collect, process, store, and distribute information to support decision making and control in an organization.” [1]
- “Information systems are combinations of hardware, software, and telecommunications networks that people build and use to collect, create, and distribute useful data, typically in organizational settings.” [2]
- “Information systems are interrelated components working together to collect, process, store, and disseminate information to support decision making, coordination, control, analysis, and visualization in an organization.” [3]
The Components of Information Systems
Information systems can be viewed as having five major components: hardware, software, data, people, and processes. The first three are technology . These are probably what you thought of when defining information systems. The last two components, people and processes, separate the idea of information systems from more technical fields, such as computer science. In order to fully understand information systems, you will need to understand how all of these components work together to bring value to an organization.
Technology can be thought of as the application of scientific knowledge for practical purposes. From the invention of the wheel to the harnessing of electricity for artificial lighting, technology has become ubiquitous in daily life, to the degree that it is assumed to always be available for use regardless of location. As discussed before, the first three components of information systems – hardware, software, and data – all fall under the category of technology. Each of these will be addressed in an individual chapter. At this point a simple introduction should help you in your understanding.
Hardware is the tangible, physical portion of an information system – the part you can touch. Computers, keyboards, disk drives, and flash drives are all examples of information systems hardware. How these hardware components function and work together will be covered in Chapter 2.
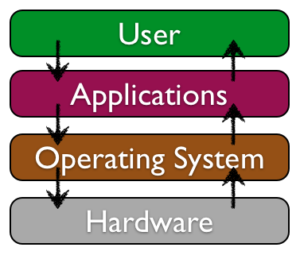
Software comprises the set of instructions that tell the hardware what to do. Software is not tangible – it cannot be touched. Programmers create software by typing a series of instructions telling the hardware what to do. Two main categories of software are: Operating Systems and Application software. Operating Systems software provides the interface between the hardware and the Application software. Examples of operating systems for a personal computer include Microsoft Windows and Ubuntu Linux. The mobile phone operating system market is dominated by Google Android and Apple iOS. Application software allows the user to perform tasks such as creating documents, recording data in a spreadsheet, or messaging a friend. Software will be explored more thoroughly in Chapter 3.
The third technology component is data. You can think of data as a collection of facts. For example, your address (street, city state, postal code), your phone number, and your social networking account are all pieces of data. Like software, data is also intangible, unable to be seen in its native state. Pieces of unrelated data are not very useful. But aggregated, indexed, and organized together into a database, data can become a powerful tool for businesses. Organizations collect all kinds of data and use it to make decisions which can then be analyzed as to their effectiveness. The analysis of data is then used to improve the organization’s performance. Chapter 4 will focus on data and databases, and how it is used in organizations.
Networking Communication
Besides the technology components (hardware, software, and data) which have long been considered the core technology of information systems, it has been suggested that one other component should be added: communication. An information system can exist without the ability to communicate – the first personal computers were stand-alone machines that did not access the Internet. However, in today’s hyper-connected world, it is an extremely rare computer that does not connect to another device or to a enetwork. Technically, the networking communication component is made up of hardware and software, but it is such a core feature of today’s information systems that it has become its own category. Networking will be covered in Chapter 5.

When thinking about information systems, it is easy to focus on the technology components and forget to look beyond these tools to fully understand their integration into an organization. A focus on the people involved in information systems is the next step. From the front-line user support staff, to systems analysts, to developers, all the way up to the chief information officer (CIO), the people involved with information systems are an essential element. The people component will be covered in Chapter 9.
The last component of information systems is process. A process is a series of steps undertaken to achieve a desired outcome or goal. Information systems are becoming more integrated with organizational processes, bringing greater productivity and better control to those processes. But simply automating activities using technology is not enough – businesses looking to utilize information systems must do more. The ultimate goal is to improve processes both internally and externally, enhancing interfaces with suppliers and customers. Technology buzzwords such as “business process re-engineering,” “business process management,” and “enterprise resource planning” all have to do with the continued improvement of these business procedures and the integration of technology with them. Businesses hoping to gain a competitive advantage over their competitors are highly focused on this component of information systems. The process element in information systems will be discussed in Chapter 8.
The Role of Information Systems
You should now understand that information systems have a number of vital components, some tangible, others intangible, and still others of a personnel nature. These components collect, store, organize, and distribute data throughout the organization. You may have even realized that one of the roles of information systems is to take data and turn it into information, and then transform that information into organizational knowledge. As technology has developed, this role has evolved into the backbone of the organization, making information systems integral to virtually every business. The integration of information systems into organizations has progressed over the decades.
The Mainframe Era
From the late 1950s through the 1960s, computers were seen as a way to more efficiently do calculations. These first business computers were room-sized monsters, with several machines linked together. The primary work was to organize and store large volumes of information that were tedious to manage by hand. Only large businesses, universities, and government agencies could afford them, and they took a crew of specialized personnel and dedicated facilities to provide information to organizations.
Time-sharing allowed dozens or even hundreds of users to simultaneously access mainframe computers from locations in the same building or miles away. Typical functions included scientific calculations and accounting, all under the broader umbrella of “data processing.”
In the late 1960s, Manufacturing Resources Planning (MRP) systems were introduced. This software, running on a mainframe computer, gave companies the ability to manage the manufacturing process, making it more efficient. From tracking inventory to creating bills of materials to scheduling production, the MRP systems gave more businesses a reason to integrate computing into their processes. IBM became the dominant mainframe company. Continued improvement in software and the availability of cheaper hardware eventually brought mainframe computers (and their little sibling, the minicomputer) into most large businesses.
Today you probably think of Silicon Valley in northern California as the center of computing and technology. But in the days of the mainframe’s dominance corporations in the cities of Minneapolis and St. Paul produced most computers. The advent of the personal computer resulted in the “center of technology” eventually moving to Silicon Valley.
The PC Revolution
In 1975, the first microcomputer was announced on the cover of Popular Mechanics : the Altair 8800. Its immediate popularity sparked the imagination of entrepreneurs everywhere, and there were soon dozens of companies manufacturing these “personal computers.” Though at first just a niche product for computer hobbyists, improvements in usability and the availability of practical software led to growing sales. The most prominent of these early personal computer makers was a little company known as Apple Computer, headed by Steve Jobs and Steve Wozniak, with the hugely successful “Apple II.” Not wanting to be left out of the revolution, in 1981 IBM teamed with Microsoft, then just a startup company, for their operating system software and hurriedly released their own version of the personal computer simply called the “PC.” Small businesses finally had affordable computing that could provide them with needed information systems. Popularity of the IBM PC gave legitimacy to the microcomputer and it was named Time magazine’s “Man of the Year” for 1982.

Because of the IBM PC’s open architecture, it was easy for other companies to copy, or “clone” it. During the 1980s, many new computer companies sprang up, offering less expensive versions of the PC. This drove prices down and spurred innovation. Microsoft developed the Windows operating system, with version 3.1 in 1992 becoming the first commercially successful release. Typical uses for the PC during this period included word processing, spreadsheets, and databases. These early PCs were standalone machines, not connected to a network.
Client-Server
In the mid-1980s, businesses began to see the need to connect their computers as a way to collaborate and share resources. Known as “client-server,” this networking architecture allowed users to log in to the Local Area Network (LAN) from their PC (the “client”) by connecting to a central computer called a “server.” The server would lookup permissions for each user to determine who had access to various resources such as printers and files. Software companies began developing applications that allowed multiple users to access the same data at the same time. This evolved into software applications for communicating, with the first popular use of electronic mail appearing at this time.

This networking and data sharing all stayed mainly within the confines of each business. Sharing of electronic data between companies was a very specialized function. Computers were now seen as tools to collaborate internally within an organization. These networks of computers were becoming so powerful that they were replacing many of the functions previously performed by the larger mainframe computers at a fraction of the cost. It was during this era that the first Enterprise Resource Planning (ERP) systems were developed and run on the client-server architecture. An ERP system is an application with a centralized database that can be used to run a company’s entire business. With separate modules for accounting, finance, inventory, human resources, and many more, ERP systems, with Germany’s SAP leading the way, represented the state of the art in information systems integration. ERP systems will be discussed in Chapter 9.
The Internet, World Wide Web and E-Commerce

The first long distance transmission between two computers occurred on October 29, 1969 when developers under the direction of Dr. Leonard Kleinrock sent the word “login” from the campus of UCLA to Stanford Research Institute in Menlo Park, California, a distance of over 350 miles. The United States Department of Defense created and funded ARPA Net (Advanced Research Projects Administration), an experimental network which eventually became known as the Internet. ARPA Net began with just four nodes or sites, a very humble start for today’s Internet. Initially, the Internet was confined to use by universities, government agencies, and researchers. Users were required to type commands (today we refer to this as “command line”) in order to communicate and transfer files. The first e-mail messages on the Internet were sent in the early 1970s as a few very large companies expanded from local networks to the Internet. The computer was now evolving from a purely computational device into the world of digital communications.
In 1989, Tim Berners-Lee developed a simpler way for researchers to share information over the Internet, a concept he called the World Wide Web . [4] This invention became the catalyst for the growth of the Internet as a way for businesses to share information about themselves. As web browsers and Internet connections became the norm, companies rushed to grab domain names and create websites.
The digital world also became a more dangerous place as virtually all companies connected to the Internet. Computer viruses and worms, once slowly propagated through the sharing of computer disks, could now grow with tremendous speed via the Internet. Software and operating systems written for a standalone world found it very difficult to defend against these sorts of threats. A whole new industry of computer and Internet security arose. Information security will be discussed in Chapter 6.
As the world recovered from the dot-com bust, the use of technology in business continued to evolve at a frantic pace. Websites became interactive. Instead of just visiting a site to find out about a business and then purchase its products, customers wanted to be able to customize their experience and interact online with the business. This new type of interactive website, where you did not have to know how to create a web page or do any programming in order to put information online, became known as Web 2.0. This new stage of the Web was exemplified by blogging, social networking, and interactive comments being available on many websites. The new Web 2.0 world, in which online interaction became expected, had a major impact on many businesses and even whole industries. Many bookstores found themselves relegated to a niche status. Video rental chains and travel agencies simply began going out of business as they were replaced by online technologies. The newspaper industry saw a huge drop in circulation with some cities such as New Orleans no longer able to support a daily newspaper. Disintermediation is the process of technology replacing a middleman in a transaction. Web 2.0 allowed users to get information and news online, reducing dependence of physical books and newspapers.
As the world became more connected, new questions arose. Should access to the Internet be considered a right? Is it legal to copy a song that had been downloaded from the Internet? Can information entered into a website be kept private? What information is acceptable to collect from children? Technology moved so fast that policymakers did not have enough time to enact appropriate laws. Ethical issues surrounding information systems will be covered in Chapter 12.
The Post-PC World, Sort of
Ray Ozzie, a technology visionary at Microsoft, stated in 2012 that computing was moving into a phase he called the post-PC world. [5] Now six years later that prediction has not stood up very well to reality. As you will read in Chapter 13, PC sales have dropped slightly in recent years while there has been a precipitous decline in tablet sales. Smartphone sales have accelerated, due largely to their mobility and ease of operation. Just as the mainframe before it, the PC will continue to play a key role in business, but its role will be somewhat diminished as people emphasize mobility as a central feature of technology. Cloud computing provides users with mobile access to data and applications, making the PC more of a part of the communications channel rather than a repository of programs and information. Innovation in the development of technology and communications will continue to move businesses forward.
Can Information Systems Bring Competitive Advantage?
It has always been the assumption that the implementation of information systems will bring a business competitive advantage. If installing one computer to manage inventory can make a company more efficient, then it can be expected that installing several computers can improve business processes and efficiency.
In 2003, Nicholas Carr wrote an article in the Harvard Business Review that questioned this assumption. Entitled “I.T. Doesn’t Matter.” Carr was concerned that information technology had become just a commodity. Instead of viewing technology as an investment that will make a company stand out, Carr said technology would become as common as electricity – something to be managed to reduce costs, ensure that it is always running, and be as risk-free as possible.
The article was both hailed and scorned. Can I.T. bring a competitive advantage to an organization? It sure did for Walmart (see sidebar). Technology and competitive advantage will be discussed in Chapter 7.
Sidebar: Walmart Uses Information Systems to Become the World’s Leading Retailer

Walmart is the world’s largest retailer, earn 8.1 billion for the fiscal year that ended on January 31, 2018. Walmart currently serves over 260 million customers every week worldwide through its 11,700 stores in 28 countries. [6] In 2018 Fortune magazine for the sixth straight year ranked Walmart the number one company for annual revenue as they again exceeded $500 billion in annual sales. The next closest company, Exxon, had less than half of Walmart’s total revenue. [7] Walmart’s rise to prominence is due in large part to making information systems a high priority, especially in their Supply Chain Management (SCM) system known as Retail Link. ing $14.3 billion on sales of $30
This system, unique when initially implemented in the mid-1980s, allowed Walmart’s suppliers to directly access the inventory levels and sales information of their products at any of Walmart’s more than eleven thousand stores. Using Retail Link, suppliers can analyze how well their products are selling at one or more Walmart stores with a range of reporting options. Further, Walmart requires the suppliers to use Retail Link to manage their own inventory levels. If a supplier feels that their products are selling out too quickly, they can use Retail Link to petition Walmart to raise the inventory levels for their products. This has essentially allowed Walmart to “hire” thousands of product managers, all of whom have a vested interest in the products they are managing. This revolutionary approach to managing inventory has allowed Walmart to continue to drive prices down and respond to market forces quickly.
Today Walmart continues to innovate with information technology. Using its tremendous market presence, any technology that Walmart requires its suppliers to implement immediately becomes a business standard. For example, in 1983 Walmart became the first large retailer to require suppliers to the use Uniform Product Code (UPC) labels on all products. Clearly, Walmart has learned how to use I.T. to gain a competitive advantage.
In this chapter you have been introduced to the concept of information systems. Several definitions focused on the main components: technology, people, and process. You saw how the business use of information systems has evolved over the years, from the use of large mainframe computers for number crunching, through the introduction of the PC and networks, all the way to the era of mobile computing. During each of these phases, new innovations in software and technology allowed businesses to integrate technology more deeply into their organizations.
Virtually every company uses information systems which leads to the question: Does information systems bring a competitive advantage? In the final analysis the goal of this book is to help you understand the importance of information systems in making an organization more competitive. Your challenge is to understand the key components of an information system and how it can be used to bring a competitive advantage to every organization you will serve in your career.
Study Questions
- What are the five major components that make up an information system?
- List the three examples of information system hardware?
- Microsoft Windows is an example of which component of information systems?
- What is application software?
- What roles do people play in information systems?
- What is the definition of a process?
- What was invented first, the personal computer or the Internet?
- In what year were restrictions on commercial use of the Internet first lifted?
- What is Carr’s main argument about information technology?
- Suppose that you had to explain to a friend the concept of an information system. How would you define it? Write a one-paragraph description in your own words that you feel would best describe an information system to your friends or family.
- Of the five primary components of an information system (hardware, software, data, people, process), which do you think is the most important to the success of a business organization? Write a one-paragraph answer to this question that includes an example from your personal experience to support your answer.
- Everyone interacts with various information systems every day: at the grocery store, at work, at school, even in our cars. Make a list of the different information systems you interact with daily. Can you identify the technologies, people, and processes involved in making these systems work.
- Do you agree that we are in a post-PC stage in the evolution of information systems? Do some original research and cite it as you make your prediction about what business computing will look like in the next generation.
- The Walmart sidebar introduced you to how information systems was used to make them the world’s leading retailer. Walmart has continued to innovate and is still looked to as a leader in the use of technology. Do some original research and write a one-page report detailing a new technology that Walmart has recently implemented or is pioneering.
- Examine your PC. Using a four column table format identify and record the following information: 1st column: Program name, 2nd column: software manufacturer, 3rd column: software version, 4th column: software type (editor/word processor, spreadsheet, database, etc.).
- Examine your mobile phone. Create another four column table similar to the one in Lab #1. This time identify the apps, then record the requested information.
- In this chapter you read about the evolution of computing from mainframe computers to PCs and on to smartphones. Create a four column table and record the following information about your own electronic devices: 1st column – Type: PC or smartphone, 2nd column – Operating system including version, 3rd column – Storage capacity, 4th column – Storage available.
- Laudon, K.C. and Laudon, J. P. (2014) Management Information Systems , thirteenth edition. Upper Saddle River, New Jersey: Pearson.
- Valacich, J. and Schneider, C. (2010). Information Systems Today – Managing in the Digital World , fourth edition. Upper Saddle River, New Jersey: Prentice-Hall.
- Laudon, K.C. and Laudon, J. P. (2012). Management Information Systems , twelfth edition. Upper Saddle River, New Jersey: Prentice-Hall.
- CERN . (n.d.) The Birth of the Web. Retrieved from http://public.web.cern.ch/public/en/about/web-en.html
- Marquis, J. (2012, July 16) What is the Post-PC World? Online Universities.com. Retrieved from https://www.onlineuniversities.com/blog/2012/07/what-post-pc-world/
- Walmart . (n.d.) 2017 Annual Report. Retrieved from http://s2.q4cdn.com/056532643/files/doc_financials/2017/Annual/WMT_2017_AR-(1).pdf
- McCoy, K. (2018, May 21). Big Winners in Fortune 500 List. USA Today . Retrieved from http://https://www.usatoday.com/story/money/2018/05/21/big-winners-fortune-500-list-walmart-exxon-mobil-amazon/628003002/
Information Systems for Business and Beyond (2019) by David Bourgeois is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License , except where otherwise noted.
Share This Book

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
Margin Size
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
1.1: Introduction to Information Systems?
- Last updated
- Save as PDF
- Page ID 84100

- David T. Bourgeois
- Biola University via Saylor Foundation
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
Learning Objectives
Upon successful completion of this chapter, you will be able to:
- define what an information system is by identifying its major components;
- describe the basic history of information systems; and
- describe the basic argument behind the article “Does IT Matter?” by Nicholas Carr.
Introduction
If you are reading this, you are most likely taking a course in information systems, but do you even know what the course is going to cover? When you tell your friends or your family that you are taking a course in information systems, can you explain what it is about? For the past several years, I have taught an Introduction to Information Systems course. The first day of class I ask my students to tell me what they think an information system is. I generally get answers such as “computers,” “databases,” or “Excel.” These are good answers, but definitely incomplete ones. The study of information systems goes far beyond understanding some technologies. Let’s begin our study by defining information systems.
Defining Information Systems
Almost all programs in business require students to take a course in something called information systems . But what exactly does that term mean? Let’s take a look at some of the more popular definitions, first from Wikipedia and then from a couple of textbooks:
- “Information systems (IS) is the study of complementary networks of hardware and software that people and organizations use to collect, filter, process, create, and distribute data.” [1]
- “Information systems are combinations of hardware, software, and telecommunications networks that people build and use to collect, create, and distribute useful data, typically in organizational settings.” [2]
- “Information systems are interrelated components working together to collect, process, store, and disseminate information to support decision making, coordination, control, analysis, and viualization in an organization.” [3]

- A-Z Databases
- Training Calendar
- Research Portal

Information Systems
- Find Journal Articles
- Internet Resources
Referencing
- Information Literacy Tutorial This link opens in a new window
- Post-Graduates
Ask your Librarian!

- About Referencing
- About Plagiarism
Harvard Referencing Style
- Reference Management Tools
What is referencing?
Referencing is a standardised method used particularly in academic writing to acknowledge the sources used in an essay or paper. "It serves as evidence from secondary sources to your research" (Badenhorst 2007, p. 21).
Where do you reference in your paper?
- In the body of your paper. This is called textual or in-text citation (examples are given on each referencing style in this guide).
- At the end of your paper. This is known as the reference list or a bibliography. You must always start your bibliography or your reference list in a new page. There is a difference between a bibliography and a reference list. A bibliography is a list of all the sources you have consulted when preparing to write your paper, it doesn't matter whether you have cited them in the body of your paper or not. A reference list is a list of only the sources you have cited in the body of your paper. Normally in academic writing, students are required to give a reference list.
What must be referenced?
Direct quotation - this is when you use the direct words of the author as they exactly appear in the text. This must be cited and enclosed in the quotation marks.
Paraphrase - This is when you take a passage from a source and re-write it in your own words but the ideas or facts you are expressing are based on what you read. This must be cited as well but is not enclosed in quotation marks.
Summary - A summary is similar to a paraphrase since you also re-write this piece of information in your own words. However with summary you select only the main ideas and and supporting details. This also needs to be referenced but is also not enclosed in quotation marks.
Why do you need to give references to your work?
- To redirect the readers of your paper to the original sources you have cited;
- To validate and give credibility to your argument;
- To distinguish between your own ideas and those of someone else's;
- To demonstrate to your lecturers the amount of reading you have done;
- To avoid being accused of plagiarism.
What is plagiarism?
Plagiarism is the act of using somebody else's ideas or words without giving credits to the originator. It is treated as an academic crime and can result in failing the whole course or being expelled from the institution. There are two kinds of plagiarism (i) Accidental plagiarism = this type of plagiarism happens when you did not intend to plagiarise but you still failed to acknowledge the sources. (ii) Blatant plagiarism = this is when you commit plagiarism deliberately - e.g. you copy and paste a passage from somebody else's assignment without acknowledging the source.
Accidental Plagiarism:
- Failing to give citation after paraphrasing or summarising;
- Referencing sources incorrectly;
- Forgetting to put a direct quote in the quotation marks;
- Using too many direct quotations constitutes plagiarism, as it indicates that you have contributed very little;
- Failing to paraphrase correctly and keep the original meaning of the passage.
Blatant Plagiarism:
- Asking somebody else to write your essay for you;
- Copy and pasting a passage from somebody else's essay without acknowledging the source;
- Stealing another person's essay and submit it as if it is yours;
- Buying somebody else's paper and submit it as if it is yours.
Harvard is also known as the Author-Date system. The author's surname and year of publication are cited in the text of your work. The full details of the book are included in a reference list at the end of the assignment.
Quick links for citing in Harvard
Citing books More about citing books
Citing journal articles Citing other types of periodicals
Emails, blogs YouTube videos, website publications
Government publications
Miscellaneous sources

EndNote is reference management software with features to keep all your references and reference-related materials in a searchable personal library.
EndNote enables researcher to:
- Promote new and ongoing research
- Provide a standardised reference management tool with access anywhere
- Track research trends, authors or topics easily
- Capture, store, and organize vast collections of research in one place
- Simplify bibliography and report creation within Microsoft® Word
- Collaborate and share research across departments and organizations globally
Endnote Installation Guide:
More information and tips on using EndNote and links to resources can be found here:
- How to Install Endnote 20 Guide
- How to Install Endnote 20 Installation Files (Shortcut)

Mendeley is a free reference manager and academic social network that serves as an information system to support research.
It can help researchers to:
- Set up, organise and manage a library;
- Find new research on the embedded search feature;
- Access, manage and share references and research data;
- Share documents and collaborate;
- Highlight and annotate documents;
- Showcase your latest research;
- Find funding, and identify career opportunities.
Mendeley Installation Guide:
Download and install
Create a free account
- << Previous: Internet Resources
- Next: Information Literacy Tutorial >>
- Last Updated: Jan 25, 2024 9:46 AM
- URL: https://libguides.uwc.ac.za/information_systems
UWC LIBRARY & INFORMATION SERVICES
Information Systems in Organizations
Introduction.
In the modern world, the majority of organizations make use of the information systems to attain information necessary for effectively improving operations in the organization and accomplishing the tasks set aside in the organization. In an organization, an information system attains the data by collecting it, storing it, and processing the data to provide accurate and substantial information. Information systems do not necessarily require to be computerized but as the modern world dictates, the majority of the information systems depend on computers, which are more efficient than manual systems.
Information systems are normally grouped according to the tasks they are supposed to accomplish. Generally, there are four types of information systems depending on the organizational level they operate in. These four general categories are discussed in the section below.
Categories of information systems
Transaction processing systems.
In the context of information systems, a transaction is defined as the process of exchange between different groups of which, it is recorded and electronically stored in a computer. A good example of a transaction processing system is ATM cash withdrawal. The majority of the operations in an organization involve the use of transactions.
In these transactions, a transaction processing system functions by dictating the means of collecting data, processing it, storing it, modifying it, displaying it, and even canceling the transaction. The databases are used to store the data attained by the transaction processing systems. The majority of the transaction processing systems can accommodate numerous transactions simultaneously. The stored data in the databases by the Transaction processing systems are used in the production of periodically scheduled reports such as monthly bills (Parsons & Oja, 2010, p. 559).
Management information systems
The management information system is a type of information system that makes use of the data attained by the transaction processing system to produce reports that are useful in the decision-making process of an organizational manager. The data obtained by the transaction processing system is manipulated to obtain the reports used in decision-making.
In an organization, different levels of management have different types of information needs and it is the function of the management information systems to tackle these needs, for instance, the information needs of the management in an organization can be tackled by the production of ad hoc reports or schedule reports (Parsons & Oja, 2010, p. 561).
Decision support systems
Middle-level managers in organizations mainly make use of decision support systems to equip them with crucial data that they will use in making decisions on behalf of the organization. The term traces its roots in the late 1970s when it was used and is still used to equip the decision-makers in an organization with the necessary tools required in modeling and accessing data. In terms of semi-structured decisions, the decision-makers mainly make use of decision support systems.
This is because in analyzing the data, the decision-makers are not always sure of the process to follow, the necessary data required, or the right tools to be used. This category of information systems is designed to indicate the effectiveness of an organization against the objectives (Grossman & Livingstone, 2009, p. 529).
Strategic information systems
Strategic information systems are mainly used in the executive decision-making process. This type of information system develops the strategic decision-making abilities of the executives in an organization. The strategic information systems are generally categorized into two, according to the type of support they offer to an organization.
The first category of support is the timely and effective information search, which is used in retrieving crucial internal and external information but the organization’s top executives. The second category of support is the facilitation of first and comprehensive analytical decisions. It is suggested that with the use of this kind of support, the decision analysis by the top executives will be enhanced without slowing down the whole process of decision-making (Zhang, 2010, p.2).
Principles of organizational information systems
In an information system, the importance of the information achieved is supposed to be as important as the organizational objectives it attains in its decision-making process. In addition to this, foreseeing the impact of the information system on the organization and putting the knowledge acquired into good use is crucial in ensuring organizational goals are met and a successful personal career is established.
To achieve a successful information system the all the concerned parties, which include the managers, professionals of information systems, and the system users must work together. Not only does the incorporation of the information system into an organization add more value to the organization it also gives the organization a competitive edge (Stair, et al, 2009, p. 2).
Users of Information systems
Information systems are incorporated in almost any type of professional in the current technological world. In advertising products, sales representatives make good use of information systems by communicating with customers as well as monitoring and analyzing the sales trends. In organizations or firms, managers incorporate information systems in decision making especially when it comes to critical decisions.
In the offering of advice to the clients on saving for the future, the financial planners make use of the information systems. In addition to this, financial and accounting operations across the various types of businesses are carried out using the information system. Regardless of the type of business one is operating information system has emerged as a critical tool of ensuring the various business goals are met. The feedback process is attributed to achieving the business goals achievement such as profit increase and improved customer service (Stair, et al, 2009, p. 4).
Information systems are designed for the sole purpose of aiding an organization in achieving effective decision-making capacities. The transaction processing systems for instance are mainly involved while dealing with repetitive operations. The information is normally analyzed and structured as the data is obtained easily and later store in large volumes.
Management information system, which is mainly used by middle-level managers, is used mainly in tracking, monitoring, and controlling the progress of the organization, which is later on reported to the senior managers. The decision support system is mainly used by managers while dealing with unstructured decisions.
The data of the decision is retrieved and analyzed in this type of information system. It is in this type of information system that a manager of an organization can undertake the “what-if analysis” due to its ability to generate various types of solutions. Cooperation between the information system personnel and the organization managers is defined as the key to releasing the full potential of a new system.
Grossman, T. and Livingstone, L. J. (2009). The Portable MBA in Finance and Accounting . NJ: John Wiley & Sons, Inc.
Parsons, J. J. and Oja, D. (2010). New Perspectives on Computer Concepts 2011 . KY: Cengage Learning, Inc.
Stair, M. R., et al (2009). Fundamentals of Information Systems. KY: Cengage Learning, Inc.
Zhang, J. M. (2010). Can Firms Improve their Bottom-line Performance from Providing Information Systems Support for Strategic Decision Making? Connecticut: Sacred Heart University.
Cite this paper
- Chicago (N-B)
- Chicago (A-D)
StudyCorgi. (2022, March 28). Information Systems in Organizations. https://studycorgi.com/information-systems-in-organizations/
"Information Systems in Organizations." StudyCorgi , 28 Mar. 2022, studycorgi.com/information-systems-in-organizations/.
StudyCorgi . (2022) 'Information Systems in Organizations'. 28 March.
1. StudyCorgi . "Information Systems in Organizations." March 28, 2022. https://studycorgi.com/information-systems-in-organizations/.
Bibliography
StudyCorgi . "Information Systems in Organizations." March 28, 2022. https://studycorgi.com/information-systems-in-organizations/.
StudyCorgi . 2022. "Information Systems in Organizations." March 28, 2022. https://studycorgi.com/information-systems-in-organizations/.
This paper, “Information Systems in Organizations”, was written and voluntary submitted to our free essay database by a straight-A student. Please ensure you properly reference the paper if you're using it to write your assignment.
Before publication, the StudyCorgi editorial team proofread and checked the paper to make sure it meets the highest standards in terms of grammar, punctuation, style, fact accuracy, copyright issues, and inclusive language. Last updated: March 28, 2022 .
If you are the author of this paper and no longer wish to have it published on StudyCorgi, request the removal . Please use the “ Donate your paper ” form to submit an essay.
Big Data: What It Is and Why It’s Important
These huge datasets reveal patterns and trends for better decision making.
What Is Big Data?
Big data refers to large, diverse data sets made up of structured, unstructured and semi-structured data. This data is generated continuously and always growing in size, which makes it too high in volume, complexity and speed to be processed by traditional data management systems.
Big Data Definition
Big data refers to massive, complex data sets that are rapidly generated and transmitted from a wide variety of sources. Big data sets can be structured, semi-structured and unstructured, and they are frequently analyzed to discover applicable patterns and insights about user and machine activity.
Big data is used across almost every industry to draw insights, perform analytics, train artificial intelligence and machine learning models, as well as help make data-driven business decisions.
Why Is Big Data Important?
Data is generated anytime we open an app, use a search engine or simply travel place to place with our mobile devices. The result? Massive collections of valuable information that companies and organizations manage, store, visualize and analyze.
Traditional data tools aren’t equipped to handle this kind of complexity and volume, which has led to a slew of specialized big data software platforms designed to manage the load.
Though the large-scale nature of big data can be overwhelming, this amount of data provides a heap of information for organizations to use to their advantage. Big data sets can be mined to deduce patterns about their original sources, creating insights for improving business efficiency or predicting future business outcomes.
As a result, big data analytics is used in nearly every industry to identify patterns and trends, answer questions, gain insights into customers and tackle complex problems. Companies and organizations use the information for a multitude of reasons like automating processes, optimizing costs, understanding customer behavior, making forecasts and targeting key audiences for advertising.
The 3 V’s of Big Data
Big data is commonly characterized by three V’s:
Volume refers to the huge amount of data that’s generated and stored. While traditional data is measured in familiar sizes like megabytes, gigabytes and terabytes, big data is stored in petabytes and zettabytes.
Variety refers to the different types of data being collected from various sources, including text, video, images and audio. Most data is unstructured, meaning it’s unorganized and difficult for conventional data tools to analyze. Everything from emails and videos to scientific and meteorological data can constitute a big data stream, each with their own unique attributes.
Big data is generated, processed and analyzed at high speeds. Companies and organizations must have the capabilities to harness this data and generate insights from it in real-time, otherwise it’s not very useful. Real-time processing allows decision makers to act quickly.

How Big Data Works
Big data is produced from multiple data sources like mobile apps, social media, emails, transactions or Internet of Things (IoT) sensors, resulting in a continuous stream of varied digital material. The diversity and constant growth of big data makes it inherently difficult to extract tangible value from it in its raw state. This results in the need to use specialized big data tools and systems, which help collect, store and ultimately translate this data into usable information. These systems make big data work by applying three main actions — integration, management and analysis.
1. Integration
Big data first needs to be gathered from its various sources. This can be done in the form of web scraping or by accessing databases, data warehouses, APIs and other data logs. Once collected, this data can be ingested into a big data pipeline architecture, where it is prepared for processing.
Big data is often raw upon collection, meaning it is in its original, unprocessed state. Processing big data involves cleaning, transforming and aggregating this raw data to prepare it for storage and analysis.
2. Management
Once processed, big data is stored and managed within the cloud or on-premises storage servers (or both). In general, big data typically requires NoSQL databases that can store the data in a scalable way, and that doesn’t require strict adherence to a particular model. This provides the flexibility needed to cohesively analyze disparate sources of data and gain a holistic view of what is happening, how to act and when to act on data.
3. Analysis
Analysis is one the final steps of the big data lifecycle, where the data is explored and analyzed to find applicable insights, trends and patterns. This is frequently carried out using big data analytics tools and software. Once useful information is found, it can be applied to make business decisions and communicated to stakeholders in the form of data visualizations.
Uses of Big Data
Here are a few examples of industries where the big data revolution is already underway:
Finance and insurance industries utilize big data and predictive analytics for fraud detection, risk assessments, credit rankings, brokerage services and blockchain technology, among other uses. Financial institutions also use big data to enhance their cybersecurity efforts and personalize financial decisions for customers.
Hospitals, researchers and pharmaceutical companies adopt big data solutions to improve and advance healthcare. With access to vast amounts of patient and population data, healthcare is enhancing treatments, performing more effective research on diseases like cancer and Alzheimer’s, developing new drugs, and gaining critical insights on patterns within population health.
Using big data in education allows educational institutions and professionals to better understand student patterns and create relevant educational programs. This can help in personalizing lesson plans, predicting learning outcomes and tracking school resources to reduce operational costs.
Retail utilizes big data by collecting large amounts of customer data through purchase and transaction histories. Information from this data is used to predict future consumer behavior and personalize the shopping experience.
Big data in government can work to gather insights on citizens from public financial, health and demographic data and adjust government actions accordingly. Certain legislation, financial procedures or crisis response plans can be enacted based on these big data insights.
Big data in marketing helps provide an overview of user and consumer behavior for businesses. Data gathered from these parties can reveal insights on market trends or buyer behavior, which can be used to direct marketing campaigns and optimize marketing strategies.
If you’ve ever used Netflix, Hulu or any other streaming services that provide recommendations , you’ve witnessed big data at work. Media companies analyze our reading, viewing and listening habits to build individualized experiences. Netflix even uses data on graphics, titles and colors to make decisions about customer preferences.
Big Data Challenges
1. volume and complexity of data.
Big data is massive, complicated and ever growing. This makes it difficult in nature to capture, organize and understand, especially as time goes on. In order to manage big data, new technologies have to be developed indefinitely and organizational big data strategies have to continually adapt.
2. Integration and Processing Requirements
Aside from storage challenges, big data also has to be properly processed, cleaned and formatted to make it useful for analysis. This can take a considerable amount of time and effort due to big data’s size, multiple data sources and combinations of structured, unstructured and semi-structured data. Processing efforts and identifying what information is useful can also be compounded in the case of excess noisy data or data corruption.
3. Cybersecurity and Privacy Risks
Big data systems can sometimes handle sensitive or personal user information, making them vulnerable to cybersecurity attacks or privacy breaches. As more personal data resides in big data storage, and at such massive scales, this raises the difficulty and costs of safeguarding this data from criminals. Additionally, how businesses collect personal data through big data systems may not comply with regional data collection laws or regulations, leading to a breach of privacy for affected users.
Big Data Technologies
Big data technologies describe the tools used to handle and manage data at enormous scales. These technologies include those used for big data analytics, collection, mining, storage and visualization.
Data Analysis Tools
Data analysis tools involve software that can be used for big data analytics, where relevant insights, correlations and patterns are identified within given data.
Big Data Tools
Big data tools refer to any data platform , database , business intelligence tool or application where large data sets are stored, processed or analyzed.
Data Visualization Tools
Data visualization tools help to display the findings extracted from big data analytics in the form of charts, graphs or dashboards.
History of Big Data
“Big data” as a term became popularized in the mid-1990s by computer scientist John Mashey, as Mashey used the term to refer to handling and analyzing massive data sets.
In 2001, Gartner analyst Doug Laney characterized big data as having three main traits of volume, velocity and variety, which came to be known as the three V’s of big data.
Starting in the 2000s, companies began conducting big data research and developing solutions to handle the influx of information coming from the internet and web applications. Google created the Google File System in 2003 and MapReduce in 2004 , both systems meant to help process large data sets. Using Google’s research on these technologies, software designer Doug Cutting and computer scientist Mike Cafarella developed Apache Hadoop in 2005, a software framework used to store and process big data sets for applications. In 2006, Amazon released Amazon Web Services (AWS), an on-demand cloud computing service that became a popular option to store data without using physical hardware.
In the 2010s, big data gained more prevalence as mobile device and tablet adoption increased. According to IBM as of 2020 , humans produce 2.5 quintillion bytes of data on a daily basis, with the world expected to produce 175 zettabytes of data by 2025. As connected devices and internet usage continue to grow, so will big data and its possibilities for enhanced analytics and real-time insights.
Recent Data Science Articles

Announcing the NeurIPS 2023 Paper Awards
Communications Chairs 2023 2023 Conference awards , neurips2023
By Amir Globerson, Kate Saenko, Moritz Hardt, Sergey Levine and Comms Chair, Sahra Ghalebikesabi
We are honored to announce the award-winning papers for NeurIPS 2023! This year’s prestigious awards consist of the Test of Time Award plus two Outstanding Paper Awards in each of these three categories:
- Two Outstanding Main Track Papers
- Two Outstanding Main Track Runner-Ups
- Two Outstanding Datasets and Benchmark Track Papers
This year’s organizers received a record number of paper submissions. Of the 13,300 submitted papers that were reviewed by 968 Area Chairs, 98 senior area chairs, and 396 Ethics reviewers 3,540 were accepted after 502 papers were flagged for ethics reviews .
We thank the awards committee for the main track: Yoav Artzi, Chelsea Finn, Ludwig Schmidt, Ricardo Silva, Isabel Valera, and Mengdi Wang. For the Datasets and Benchmarks track, we thank Sergio Escalera, Isabelle Guyon, Neil Lawrence, Dina Machuve, Olga Russakovsky, Hugo Jair Escalante, Deepti Ghadiyaram, and Serena Yeung. Conflicts of interest were taken into account in the decision process.
Congratulations to all the authors! See Posters Sessions Tue-Thur in Great Hall & B1-B2 (level 1).
Outstanding Main Track Papers
Privacy Auditing with One (1) Training Run Authors: Thomas Steinke · Milad Nasr · Matthew Jagielski
Poster session 2: Tue 12 Dec 5:15 p.m. — 7:15 p.m. CST, #1523
Oral: Tue 12 Dec 3:40 p.m. — 4:40 p.m. CST, Room R06-R09 (level 2)
Abstract: We propose a scheme for auditing differentially private machine learning systems with a single training run. This exploits the parallelism of being able to add or remove multiple training examples independently. We analyze this using the connection between differential privacy and statistical generalization, which avoids the cost of group privacy. Our auditing scheme requires minimal assumptions about the algorithm and can be applied in the black-box or white-box setting. We demonstrate the effectiveness of our framework by applying it to DP-SGD, where we can achieve meaningful empirical privacy lower bounds by training only one model. In contrast, standard methods would require training hundreds of models.
Are Emergent Abilities of Large Language Models a Mirage? Authors: Rylan Schaeffer · Brando Miranda · Sanmi Koyejo
Poster session 6: Thu 14 Dec 5:00 p.m. — 7:00 p.m. CST, #1108
Oral: Thu 14 Dec 3:20 p.m. — 3:35 p.m. CST, Hall C2 (level 1)
Abstract: Recent work claims that large language models display emergent abilities, abilities not present in smaller-scale models that are present in larger-scale models. What makes emergent abilities intriguing is two-fold: their sharpness, transitioning seemingly instantaneously from not present to present, and their unpredictability , appearing at seemingly unforeseeable model scales. Here, we present an alternative explanation for emergent abilities: that for a particular task and model family, when analyzing fixed model outputs, emergent abilities appear due to the researcher’s choice of metric rather than due to fundamental changes in model behavior with scale. Specifically, nonlinear or discontinuous metrics produce apparent emergent abilities, whereas linear or continuous metrics produce smooth, continuous, predictable changes in model performance. We present our alternative explanation in a simple mathematical model, then test it in three complementary ways: we (1) make, test and confirm three predictions on the effect of metric choice using the InstructGPT/GPT-3 family on tasks with claimed emergent abilities, (2) make, test and confirm two predictions about metric choices in a meta-analysis of emergent abilities on BIG-Bench; and (3) show how to choose metrics to produce never-before-seen seemingly emergent abilities in multiple vision tasks across diverse deep networks. Via all three analyses, we provide evidence that alleged emergent abilities evaporate with different metrics or with better statistics, and may not be a fundamental property of scaling AI models.
Outstanding Main Track Runner-Ups
Scaling Data-Constrained Language Models Authors : Niklas Muennighoff · Alexander Rush · Boaz Barak · Teven Le Scao · Nouamane Tazi · Aleksandra Piktus · Sampo Pyysalo · Thomas Wolf · Colin Raffel
Poster session 2: Tue 12 Dec 5:15 p.m. — 7:15 p.m. CST, #813
Oral: Tue 12 Dec 3:40 p.m. — 4:40 p.m. CST, Hall C2 (level 1)
Abstract : The current trend of scaling language models involves increasing both parameter count and training dataset size. Extrapolating this trend suggests that training dataset size may soon be limited by the amount of text data available on the internet. Motivated by this limit, we investigate scaling language models in data-constrained regimes. Specifically, we run a large set of experiments varying the extent of data repetition and compute budget, ranging up to 900 billion training tokens and 9 billion parameter models. We find that with constrained data for a fixed compute budget, training with up to 4 epochs of repeated data yields negligible changes to loss compared to having unique data. However, with more repetition, the value of adding compute eventually decays to zero. We propose and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters. Finally, we experiment with approaches mitigating data scarcity, including augmenting the training dataset with code data or removing commonly used filters. Models and datasets from our 400 training runs are freely available at https://github.com/huggingface/datablations .
Direct Preference Optimization: Your Language Model is Secretly a Reward Model Authors: Rafael Rafailov · Archit Sharma · Eric Mitchell · Christopher D Manning · Stefano Ermon · Chelsea Finn
Poster session 6: Thu 14 Dec 5:00 p.m. — 7:00 p.m. CST, #625
Oral: Thu 14 Dec 3:50 p.m. — 4:05 p.m. CST, Ballroom A-C (level 2)
Abstract: While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF). However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model. In this paper, we leverage a mapping between reward functions and optimal policies to show that this constrained reward maximization problem can be optimized exactly with a single stage of policy training, essentially solving a classification problem on the human preference data. The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for fitting a reward model, sampling from the LM during fine-tuning, or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods. Notably, fine-tuning with DPO exceeds RLHF’s ability to control sentiment of generations and improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train.
Outstanding Datasets and Benchmarks Papers
In the dataset category :
ClimSim: A large multi-scale dataset for hybrid physics-ML climate emulation
Authors: Sungduk Yu · Walter Hannah · Liran Peng · Jerry Lin · Mohamed Aziz Bhouri · Ritwik Gupta · Björn Lütjens · Justus C. Will · Gunnar Behrens · Julius Busecke · Nora Loose · Charles Stern · Tom Beucler · Bryce Harrop · Benjamin Hillman · Andrea Jenney · Savannah L. Ferretti · Nana Liu · Animashree Anandkumar · Noah Brenowitz · Veronika Eyring · Nicholas Geneva · Pierre Gentine · Stephan Mandt · Jaideep Pathak · Akshay Subramaniam · Carl Vondrick · Rose Yu · Laure Zanna · Tian Zheng · Ryan Abernathey · Fiaz Ahmed · David Bader · Pierre Baldi · Elizabeth Barnes · Christopher Bretherton · Peter Caldwell · Wayne Chuang · Yilun Han · YU HUANG · Fernando Iglesias-Suarez · Sanket Jantre · Karthik Kashinath · Marat Khairoutdinov · Thorsten Kurth · Nicholas Lutsko · Po-Lun Ma · Griffin Mooers · J. David Neelin · David Randall · Sara Shamekh · Mark Taylor · Nathan Urban · Janni Yuval · Guang Zhang · Mike Pritchard
Poster session 4: Wed 13 Dec 5:00 p.m. — 7:00 p.m. CST, #105
Oral: Wed 13 Dec 3:45 p.m. — 4:00 p.m. CST, Ballroom A-C (level 2)
Abstract: Modern climate projections lack adequate spatial and temporal resolution due to computational constraints. A consequence is inaccurate and imprecise predictions of critical processes such as storms. Hybrid methods that combine physics with machine learning (ML) have introduced a new generation of higher fidelity climate simulators that can sidestep Moore’s Law by outsourcing compute-hungry, short, high-resolution simulations to ML emulators. However, this hybrid ML-physics simulation approach requires domain-specific treatment and has been inaccessible to ML experts because of lack of training data and relevant, easy-to-use workflows. We present ClimSim, the largest-ever dataset designed for hybrid ML-physics research. It comprises multi-scale climate simulations, developed by a consortium of climate scientists and ML researchers. It consists of 5.7 billion pairs of multivariate input and output vectors that isolate the influence of locally-nested, high-resolution, high-fidelity physics on a host climate simulator’s macro-scale physical state. The dataset is global in coverage, spans multiple years at high sampling frequency, and is designed such that resulting emulators are compatible with downstream coupling into operational climate simulators. We implement a range of deterministic and stochastic regression baselines to highlight the ML challenges and their scoring. The data (https://huggingface.co/datasets/LEAP/ClimSim_high-res) and code (https://leap-stc.github.io/ClimSim) are released openly to support the development of hybrid ML-physics and high-fidelity climate simulations for the benefit of science and society.
In the benchmark category :
DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models
Authors: Boxin Wang · Weixin Chen · Hengzhi Pei · Chulin Xie · Mintong Kang · Chenhui Zhang · Chejian Xu · Zidi Xiong · Ritik Dutta · Rylan Schaeffer · Sang Truong · Simran Arora · Mantas Mazeika · Dan Hendrycks · Zinan Lin · Yu Cheng · Sanmi Koyejo · Dawn Song · Bo Li
Poster session 1: Tue 12 Dec 10:45 a.m. — 12:45 p.m. CST, #1618
Oral: Tue 12 Dec 10:30 a.m. — 10:45 a.m. CST, Ballroom A-C (Level 2)
Abstract: Generative Pre-trained Transformer (GPT) models have exhibited exciting progress in capabilities, capturing the interest of practitioners and the public alike. Yet, while the literature on the trustworthiness of GPT models remains limited, practitioners have proposed employing capable GPT models for sensitive applications to healthcare and finance – where mistakes can be costly. To this end, this work proposes a comprehensive trustworthiness evaluation for large language models with a focus on GPT-4 and GPT-3.5, considering diverse perspectives – including toxicity, stereotype bias, adversarial robustness, out-of-distribution robustness, robustness on adversarial demonstrations, privacy, machine ethics, and fairness. Based on our evaluations, we discover previously unpublished vulnerabilities to trustworthiness threats. For instance, we find that GPT models can be easily misled to generate toxic and biased outputs and leak private information in both training data and conversation history. We also find that although GPT-4 is usually more trustworthy than GPT-3.5 on standard benchmarks, GPT-4 is more vulnerable given jailbreaking system or user prompts, potentially due to the reason that GPT-4 follows the (misleading) instructions more precisely. Our work illustrates a comprehensive trustworthiness evaluation of GPT models and sheds light on the trustworthiness gaps. Our benchmark is publicly available at https://decodingtrust.github.io/.
Test of Time
This year, following the usual practice, we chose a NeurIPS paper from 10 years ago to receive the Test of Time Award, and “ Distributed Representations of Words and Phrases and their Compositionality ” by Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean, won.
Published at NeurIPS 2013 and cited over 40,000 times, the work introduced the seminal word embedding technique word2vec. Demonstrating the power of learning from large amounts of unstructured text, the work catalyzed progress that marked the beginning of a new era in natural language processing.
Greg Corrado and Jeffrey Dean will be giving a talk about this work and related research on Tuesday, 12 Dec at 3:05 – 3:25 pm CST in Hall F.
Related Posts
2023 Conference
Announcing NeurIPS 2023 Invited Talks
Reflections on the neurips 2023 ethics review process, neurips newsletter – november 2023.
Purpose of Health Information Systems Essay
Health informatics, purpose of health information systems, affect on healthcare disciplines, works cited.
According to Chakalackal, “health informatics is an evolving scientific discipline that deals with the collection, storage, retrieval, communication and optimal use of health related data, information and knowledge”. According to this definition, the scope of health informatics includes the use of methods and technologies to help solve problems or help make decisions related to healthcare. (Chakalackal, p1)
Health Information Systems are now being used the world over to aid in the operational and strategic decision making. However the implementation of these information systems may vary in scope and size from company to company. Basically the core aim of any information system is to aid the user in some way (Hovenga, Kidd, & Cesnik, p2). For Health Information Systems, the Information System helps is managing the hospital better, take ‘expert’ decisions for healthcare delivery, reduce health administration costs, increasing the quality of service and increasing customer satisfaction. (Chakalackal, p1)
Now when we look at the trends apparent in the current times and the times to come, several factors cannot be ignored. One such factor is the ageing of population and higher number of older people amidst us. This fact translates into a few things that include, a higher number of healthcare people required, need for quicker healthcare delivery, more old/nursing homes required, more drugs and medicines required to meet the need. With human life spans expected to grow to 85 years very soon, one expects the world to become a very crowded place where young and old both would require looking after. For this faster computers will be required that would store information in real time. Decision Support Systems will need to be installed so that human resources can be mobilized where they are most needed. (Hersh, p288)
Another trend that has been in continuous development is the integration of technology with more information need. Technology has been evolving to incorporate information of the patient. This includes patient history, hereditary issues, habits, eating and drinking routines, exercising habits etc.
What this means is that very soon our world will be connected by a single computer where the computer will be recording all such information from our body and storing it where the hospital (or any other institution) can retrieve it in a case of need. This won’t only allow a faster information delivery, but also a chance for the physicians to make decisions quicker (Herrick & Patterson, p26-31). But for this to happen, micro technology and PDAs must progress further to embed with humans, which is likely to incur further research and development costs. (Stead, p135-145)
Healthcare disciplines are also going through a transformation due to the changes we have seen in demographic trends due to bigger life spans and technological changes into going towards a paperless electronic world. Considering the higher lifespan issue first, we can see a higher need for healthcare professionals meaning more students need to be enrolled in this area. Also the imminent shortage of healthcare professionals also calls for multitasking and multi-skilling so that one trained doctor can take care of several patients at the same time.
This is where the information systems can help with communication and collaboration with patients and doctors remotely. Technology can be allowed to collect patient information, analyze it and give expert opinions on the best possible choice. Going electronic would mean to digitize existing documentation while training employees to do everything electronically so that information systems can pick information and analyze it promptly and in an unbiased manner. (Herrick & Patterson, p26-31)
Chakalackal, J. P. (2001). “Health Informatics”. IHS Net. Web.
Herrick, M. W., & Patterson, A. “Megatrends you need to know about” (Healthcare trends special report). Journal of AHIMA. (2000): 71(5), 26-31.
Hersh, W. R. “Improving health care through information”. Journal of the American Medical Association. (2002): 288(16).
Hovenga, E., Kidd, M., & Cesnik, B. Health informatics: An overview. Chapter II. Australia. Churchill Livingstone. (1996).
Painter, K. “ Male life span increasing ”. USA Today. Web.
Stead, W. W., Miller, R. A., Musen, M. A., & Hersh, W. R. “Integration and Beyond”. Journal of the American Medical Informatics Association. (2000): 7, 135-145.
- Importance of Nursing Informatics
- Nursing Informatics: Definition and Development
- Participatory Healthcare Informatics
- Importance of Medicare in Healthcare Field Analysis
- Applications for Health Care Administration
- IT Strategy and Alignment: Issues in Health Care Organizations: Methodology and Data Collection
- Identifying IT Infrastructures
- Models of Health Informatics Evaluation
- Chicago (A-D)
- Chicago (N-B)
IvyPanda. (2022, March 4). Purpose of Health Information Systems. https://ivypanda.com/essays/purpose-of-health-information-systems/
"Purpose of Health Information Systems." IvyPanda , 4 Mar. 2022, ivypanda.com/essays/purpose-of-health-information-systems/.
IvyPanda . (2022) 'Purpose of Health Information Systems'. 4 March.
IvyPanda . 2022. "Purpose of Health Information Systems." March 4, 2022. https://ivypanda.com/essays/purpose-of-health-information-systems/.
1. IvyPanda . "Purpose of Health Information Systems." March 4, 2022. https://ivypanda.com/essays/purpose-of-health-information-systems/.
Bibliography
IvyPanda . "Purpose of Health Information Systems." March 4, 2022. https://ivypanda.com/essays/purpose-of-health-information-systems/.
Advertisement
Supported by
There’s a New Covid Variant. What Will That Mean for Spring and Summer?
Experts are closely watching KP.2, now the leading variant.
- Share full article

By Dani Blum
For most of this year, the JN.1 variant of the coronavirus accounted for an overwhelming majority of Covid cases . But now, an offshoot variant called KP.2 is taking off. The variant, which made up just one percent of cases in the United States in mid-March, now makes up over a quarter.
KP.2 belongs to a subset of Covid variants that scientists have cheekily nicknamed “FLiRT,” drawn from the letters in the names of their mutations. They are descendants of JN.1, and KP.2 is “very, very close” to JN.1, said Dr. David Ho, a virologist at Columbia University. But Dr. Ho has conducted early lab tests in cells that suggest that slight differences in KP.2’s spike protein might make it better at evading our immune defenses and slightly more infectious than JN.1.
While cases currently don’t appear to be on the rise, researchers and physicians are closely watching whether the variant will drive a summer surge.
“I don’t think anybody’s expecting things to change abruptly, necessarily,” said Dr. Marc Sala, co-director of the Northwestern Medicine Comprehensive Covid-19 Center in Chicago. But KP.2 will most likely “be our new norm,’” he said. Here’s what to know.
The current spread of Covid
Experts said it would take several weeks to see whether KP.2 might lead to a rise in Covid cases, and noted that we have only a limited understanding of how the virus is spreading. Since the public health emergency ended , there is less robust data available on cases, and doctors said fewer people were using Covid tests.
But what we do know is reassuring: Despite the shift in variants, data from the C.D.C. suggests there are only “minimal ” levels of the virus circulating in wastewater nationally, and emergency department visits and hospitalizations fell between early March and late April.
“I don’t want to say that we already know everything about KP.2,” said Dr. Ziyad Al-Aly, the chief of research and development at the Veterans Affairs St. Louis Healthcare System. “But at this time, I’m not seeing any major indications of anything ominous.”
Protection from vaccines and past infections
Experts said that even if you had JN.1, you may still get reinfected with KP.2 — particularly if it’s been several months or longer since your last bout of Covid.
KP.2 could infect even people who got the most updated vaccine, Dr. Ho said, since that shot targets XBB.1.5, a variant that is notably different from JN.1 and its descendants. An early version of a paper released in April by researchers in Japan suggested that KP.2 might be more adept than JN.1 at infecting people who received the most recent Covid vaccine. (The research has not yet been peer-reviewed or published.) A spokesperson for the C.D.C. said the agency was continuing to monitor how vaccines perform against KP.2.
Still, the shot does provide some protection, especially against severe disease, doctors said, as do previous infections. At this point, there isn’t reason to believe that KP.2 would cause more severe illness than other strains, the C.D.C. spokesperson said. But people who are 65 and older, pregnant or immunocompromised remain at higher risk of serious complications from Covid.
Those groups, in particular, may want to get the updated vaccine if they haven’t yet, said Dr. Peter Chin-Hong, an infectious disease specialist at the University of California, San Francisco. The C.D.C. has recommended t hat people 65 and older who already received one dose of the updated vaccine get an additional shot at least four months later.
“Even though it’s the lowest level of deaths and hospitalizations we’ve seen, I’m still taking care of sick people with Covid,” he said. “And they all have one unifying theme, which is that they’re older and they didn’t get the latest shot.”
The latest on symptoms and long Covid
Doctors said that the symptoms of both KP.2 and JN.1 — which now makes up around 16 percent of cases — are most likely similar to those seen with other variants . These include sore throat, runny nose, coughing, head and body aches, fever, congestion, fatigue and in severe cases, shortness of breath. Fewer people lose their sense of taste and smell now than did at the start of the pandemic, but some people will still experience those symptoms.
Dr. Chin-Hong said that patients were often surprised that diarrhea, nausea and vomiting could be Covid symptoms as well, and that they sometimes confused those issues as signs that they had norovirus .
For many people who’ve already had Covid, a reinfection is often as mild or milder than their first case. While new cases of long Covid are less common now than they were at the start of the pandemic, repeat infections do raise the risk of developing long Covid, said Fikadu Tafesse, a virologist at Oregon Health & Science University. But researchers are still trying to determine by how much — one of many issues scientists are trying to untangle as the pandemic continues to evolve.
“That’s the nature of the virus,” Dr. Tafesse said. “It keeps mutating.”
Dani Blum is a health reporter for The Times. More about Dani Blum
VIVOTE – Election System of the Virgin Islands
Government of the Virgin Islands

DEADLINE TO SUBMIT NOMINATION PETITIONS AND PAPERS TUESDAY, MAY 21, 2024
Supervisor of Elections Caroline F. Fawkes is reminding aspirants the last day to submit Nomination Petitions and Papers is Tuesday, May 21, 2024, by 6:00 PM .
The Thomas ( Lockhart Gardens (Upstairs Banco Popular) and St. Croix Elections Offices (Sunny Isles Shopping Center, Unit 26 1 st Floor) will remain open until 6:00 PM . The St. John Elections office (Market Place Suite II) will remain open until 4:00 PM. Aspirants from St. John can file their nomination petition/paper in the St. Thomas office.
Supervisor Fawkes encourages aspirants to submit their packages in a timely fashion and feel free to ask questions regarding the process.
Official election updates can be found at the website www.vivote.gov . For questions or concerns please contact the Supervisor of Elections at (340) 773-1021, for any additional information.
Remember Your Voice is Your Vote and Your Vote is Your Voice

2024 UnOfficial STT/STJ & STX Nomination Petitions/Papers
Aspirant Listing as of Tuesday, May 21, 2024 Supervisor of Elections, Caroline F. Fawkes, announces 2024 UnOfficial STT/STJ & STX NominationPetitions/Papers Aspirant Listing as of Tuesday, May 21, 2024. See
Supervisor of Elections Caroline F. Fawkes is reminding aspirants the last day to submit Nomination Petitions and Papers is Tuesday, May 21, 2024, by 6:00 PM. The Thomas (Lockhart Gardens
Nomination Petitions/Papers Remain Available for Two Days
Supervisor of Elections Caroline F. Fawkes is reminding aspirants regarding the availability of Nomination Papers and Petitions for the 2024 Elections in accordance with Title 18 Virgin Islands Code until
Supervisor of Elections Caroline F. Fawkes is reminding aspirants the last day to submit Nomination Petitions and Papers is Tuesday, May 21, 2024, by 6:00 PM. Office hours and locations
List of Inactive Voters as of April 30, 2024
Supervisor of Elections, Caroline F. Fawkes, is providing a quarterly update regarding the list of voters whose registration status is inactive as of April 30, 2024. Supervisor Fawkes encourages these
FIRST DAY TO SUBMIT NOMINATION PETITIONS AND PAPERS IS TUESDAY, MAY 14, 2024, BEGINNING 12:00 PM
Supervisor of Elections Caroline F. Fawkes is reminding aspirants the first day to submit Nomination Petitions and Papers is Tuesday, May 14, 2024, beginning at 12:00 PM. The deadline to
IMAGES
VIDEO
COMMENTS
information system, an integrated set of components for collecting, storing, and processing data and for providing information, knowledge, and digital products.Business firms and other organizations rely on information systems to carry out and manage their operations, interact with their customers and suppliers, and compete in the marketplace.
An information system is made up of five components: hardware, software, data, people, and process. The physical parts of computing devices - those that you can actually touch - are referred to as hardware. In this chapter, we will take a look at this component of information systems, learn a little bit about how it works, and discuss some ...
An information system (IS) is a set of interrelated components that collect, manipulate, store and disseminate information and provide a feedback mechanism. to achieve a goal. The feedback ...
An ERP system is an application with a centralized database that can be used to run a company's entire business. With separate modules for accounting, finance, inventory, human resources, and many more, ERP systems, with Germany's SAP leading the way, represented the state of the art in information systems integration.
Let's take a look at some of the more popular definitions, first from Wikipedia and then from a couple of textbooks: "Information systems (IS) is the study of complementary networks of hardware and software that people and organizations use to collect, filter, process, create, and distribute data.". [1]
Exclusively available on IvyPanda. An information system (IS) is a system that allows you to store, search, and process any information. It also includes the resources and tools that enable these activities. It is necessary to access and communicate important information quickly: for example, stores have databases of their products, and ...
An information system (IS) is a formal, sociotechnical, organizational system designed to collect, process, store, and distribute information. From a sociotechnical perspective, information systems are composed by four components: task, people, structure (or roles), and technology. Information systems can be defined as an integration of components for collection, storage and processing of data ...
The purpose of this paper is to briefly discuss data, information, and knowledge. Then, the pros and cons of a leader being always available for his or her employees and clients will be addressed. Finally, some facts about robots replacing human labor in the future will be provided. We will write a custom essay on your topic.
5. Importance of Information System in Organizations. Managers must have relevant information that increases their knowledge of internal processes and external business environment. This knowledge reduces the degree of uncertainty and makes managerial decisions more rational and practical.
Information Systems for Healthcare Management Of the many enterprises that rely on information systems to attain their objectives, healthcare management is the most challenging and costly. The combination of highly complex application, systems and platform trade-offs, along with the need for continual government compliance makes information systems in healthcare one of the most difficult areas ...
Databases and data warehouses. This component is where the "material" that the other components work with resides. A database is a place where data is collected and from which it can be retrieved by querying it using one or more specific criteria. A data warehouse contains all of the data in whatever form that an organization needs.
The importance of Information Systems (IS) Example essay. Last modified: 9th Aug 2021. In this essay there will be brief introductions of these fundamental concepts and then there will be a case study of Volvo's Knowledge Management System, the VPS which highlight the importance of information system and information management in an ...
Introduction. Information systems are systems within a business organization that integrate business processes and computing knowledge for processing, storing, and transmission of important information for the decision-making process in the organization. Management information provides information on performance issues and suggests mitigation ...
1. Information Systems. Information systems (IS) involve a variety of in-. formation technologies (IT) such as computers, s oft-. ware, databases, communication systems, the Inter-. net, mobile ...
Referencing is a standardised method used particularly in academic writing to acknowledge the sources used in an essay or paper. "It serves as evidence from secondary sources to your research" (Badenhorst 2007, p. 21). Where do you reference in your paper? In the body of your paper. This is called textual or in-text citation (examples are given ...
Information System Essay. 1. Introduction It is generally accepted that information is a vital commodity for the successful operation of today's organizations. Nowadays modern business organizations are using computerized information systems in order to obtain such information. However as the technology advances rapidly the main issue is how ...
The paper argues to for the need to develop an additional, alternative sociomaterial conceptualization of IS based on a non-dualist, relational ontology. This paper aims to advance understanding of information systems (IS) through a critical reflection on how IS are currently defined in the IS literature. Using the hermeneutic approach for conducting literature reviews the paper identifies 34 ...
This essay begins by discussing the situation of blind people in nineteenth-century Europe. It then describes the invention of Braille and the gradual process of its acceptance within blind education. Subsequently, it explores the wide-ranging effects of this invention on blind people's social and cultural lives.
Transaction processing systems. In the context of information systems, a transaction is defined as the process of exchange between different groups of which, it is recorded and electronically stored in a computer. A good example of a transaction processing system is ATM cash withdrawal. The majority of the operations in an organization involve ...
Information systems (IS) and information technology (IT) are closely related disciplines that are often mistaken for one another. IS focuses more closely on information handling processes while IT tends to center the technologies that support those processes. Despite some overlap in concepts and practices, each field of study is unique.
Databases: Their Creation, Management and Utilization. Information systems are the software and hardware systems that support data-intensive applications. The journal Information Systems publishes articles concerning the design and implementation of languages, data models, process models, algorithms, software and hardware for information systems.
This results in the need to use specialized big data tools and systems, which help collect, store and ultimately translate this data into usable information. These systems make big data work by applying three main actions — integration, management and analysis. 1. Integration . Big data first needs to be gathered from its various sources.
We are honored to announce the award-winning papers for NeurIPS 2023! This year's prestigious awards consist of the Test of Time Award plus two Outstanding Paper Awards in each of these three categories: Two Outstanding Main Track Papers. Two Outstanding Main Track Runner-Ups. Two Outstanding Datasets and Benchmark Track Papers.
The Neural Information Processing Systems Foundation is a non-profit corporation whose purpose is to foster the exchange of research advances in Artificial Intelligence and Machine ... symposia, and oral and poster presentations of refereed papers. Along with the conference is a professional exposition focusing on machine learning in practice ...
Purpose of Health Information Systems. Health Information Systems are now being used the world over to aid in the operational and strategic decision making. However the implementation of these information systems may vary in scope and size from company to company. Basically the core aim of any information system is to aid the user in some way ...
Doctors said that the symptoms of both KP.2 and JN.1 — which now makes up around 16 percent of cases — are most likely similar to those seen with other variants. These include sore throat ...
Supervisor of Elections Caroline F. Fawkes is reminding aspirants the last day to submit Nomination Petitions and Papers is Tuesday, May 21, 2024, by 6:00 PM.. The Thomas (Lockhart Gardens (Upstairs Banco Popular) and St. Croix Elections Offices (Sunny Isles Shopping Center, Unit 26 1st Floor) will remain open until 6:00 PM.The St. John Elections office (Market Place Suite II) will remain open ...